
코딩테스트에 대해서 글을 작성해보고자 한다. ArrayList, LinkedList 관련해서 작성 하려고 합니다.
그날 공부한 내용을 블로그+Git + Jupyter Notebook을 선택해서 기록하기로 했다.
일단 코테를 공부하기 전에 기본 자바문법을 숙지한 상태에서 공부를 시작하였다.
매일 포스팅할 내용은 남을 위해 보여주기 보다는 어떤 공부를 했고 그리고 어떤식으로 숙지했는지 기록용도로 적어보고자 한다. 그래서 남이 보기엔 When, What, How를 기초에서 적지 않아 남이 보기엔 이해하기 어렵다는 의미이다.
코딩 테스트를 준비하려면 기본 자바 문법만이 아닌 코딩 테스트에 필요한 기술적 이론을 10일 학습을 하고 정리해보려고 한다.
자료구조
| 배열 | 스택 | 큐 |
| 링크드리스트 | 힙 | 해쉬테이블 |
알고리즘
| 정렬 | 탐색 | 동적 | 그래프 |
| 그리디(탐욕) | 분할정복 | 백트래킹 | (시간 복잡도) |
공부는 자바로 하였다. 향간에 파이썬과 C++은 코딩테스트에 유리하다고 했지만 지금까지 백앤드를 자바로 공부하였기 때문에 자바로 코딩테스트도 공부하기로 했다.
배열에서 Array 공부는 프로젝트를 하다 보면 많이 써봤기 때문에 넘어가기로 한다. 문제를 풀어보다가 배열 지식이 부족하다고 느껴지면 나중에 다시 정리해보기로 한다.
스택과 큐는 기사 실기를 준비하면서 공부를 했고 배열로 스택과 큐를 구현을 해보았기 때문에 배열과 같이 문제를 풀다가 관련 사전 지식이 부족하다고 느껴지면 다시 정리하기로 한다.
오늘은 링크드 리스트에 대해 배운 내용을 정리한다.
Linkedlist에 대해서…
링크드리스트는 말그대로 리스트의 종류이다.우리가 리스트를 사용하는 이유는 여러가지 데이터를 하나의 객체 혹은 선언된 변수에 담기 위해 리스트를 사용한다. 선언된 변수 혹은 객체는 주소를 갖고 있다. 객체의 주소를 사용하는 이유는 가시적 관점으로는 의미가 없지만 컴퓨터 내부적 구조를 생각하면 필요한 요소이다. 예를 들면 프로그래밍시 우리가 변수를 선언하면서 컴퓨터에 선언된 자료형을 기준으로 메모리가 사용된다. int, double등 각 자료형마다 정의된 메모리가 사용되고 한 변수에는 자료형에 따라 최대 8bit까지 메모리에 할당된다. 그럼, Java에서 리스트는 어떠한 메모리 할당이 될까?
자바에서 리스트를 사용할 때는 여러가지 방법이 있다.
고정된 크기의 배열로
int[] a= new int[5]; a[0] = 1; a[1] = 2; a[2] = 3; a[3] = 4; a[4] = 5; System.out.println(Arrays.toString(a));
[1, 2, 3, 4, 5]
와 같이 고정된 크기(정적 크기)의 배열로 데이터를 넣을 수 있고
동적으로 메모리 할당을 원할시에는 ArrayList와 LinkedList로 사용할 수 있다.
동적으로 할당한다고 해서 두개의 리스트(ArrayList, Linkedlist)가 가변적 데이터 크기라는 말은 아니다.
ArrayList를 기준으로 말하고자 할때 아래와 같이 stackoverflow를 참고해서 설명하고자 한다.
(출처: java – What’s meant by parameter (int initial capacity) in an arraylist – Stack Overflow)
import java.lang.reflect.Field;
import java.util.ArrayList;
public class Test {
public static void main(String[] args) throws Exception {
ArrayList<Integer> arr = new ArrayList<>();
System.out.println("initial size = " + arr.size()); //0
System.out.println("initial capacity = " + getCapacity(arr));
for ( int i = 0; i < 11; i++)
arr.add(i);
System.out.println("size = "+ arr.size()); //11
System.out.println("capacity = " + getCapacity(arr)); //15
}
static int getCapacity(ArrayList<?> l) throws Exception {
Field dataField = ArrayList.class.getDeclaredField("elementData");
dataField.setAccessible(true);
return ((Object[]) dataField.get(l)).length;
}
}
(출처: java- What’s meant by parameter(int initial capacity) in an arraylist – Stack Overflow)
ArrayList<Integer> arr = new ArrayList<>(5);
요런식으로 정의할 수 있으나 그건 의미 없는 소리고…(여기서 의미없는 소리는 ArrayList 정의에 관련된 내용이다.
다른 블로그에서는 저렇게 초기값을 설정해 두면 메모리 할당에 효율적이라고들 한다.)
어쨋든 위코드의 결과값을 보면 ArrayList는 즉 10의 초기 할당 공간을 기준으로 데이터를 동적으로 넣으면서 크기가 가변적으로 변하는 것이다. 정확하게 할당 공간이 데이터가 동적으로 넣어지면서 변하는 기준은 아직 잘 모르겠지만
int[] a와 같이 정적인 공간 할당이 아니라는 소리이다.
우리가 누군가에게 설명을 할때 정확한 기준을 알아야 한다.
즉 ArrayList의 데이터가 10개가 들어가 있으면 사이즈(or 길이)는 10이고 가변적인 할당 공간으로 데이터를 동적으로 넣을 수 있다고 설명하면 된다. 즉 ArrayList는 데이터를 지속적으로 넣으면서 메모리 공간이 커짐에 따라 지속적으로 늘어나는 메모리 공간을 낭비하지 않기 위해 크기에 따른 Capacity(할당 공간)이 적절하게 변하는 것이다.
리스트를 설명하면서 주소와 공간의 개념을 설명하다가 내용이 산으로 간것 같다 …
일단 다시 주제로 넘어가자면
자바 List는 크게 ArrayList와 LinkedList가 있다.
ArrayList는 index가 있고 LinkedList 각 원소마다 데이터와 주소값을 가지고 있다.
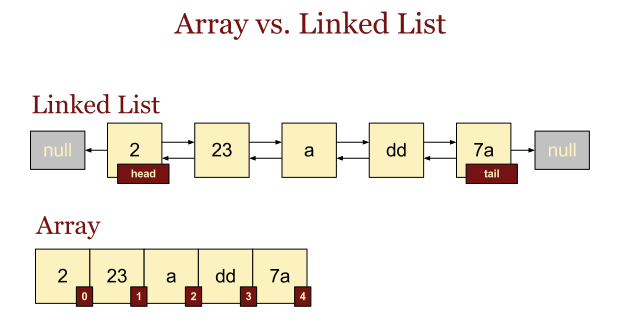
![출처:[JAVA] ArrayList와 LinkedList의 차이 :: Gyun's 개발일지 (tistory.com)](https://blog.kakaocdn.net/dn/b25oEn/btrPIICTfyo/XAkjL6JTHOPXQ97kzeuy5k/img.png)
위와 같이 시간 복잡도를 비교하면 ArrayList와 LinkedList의 가장 큰차이는
index값으로 삽입 삭제시 LinkedList의 퍼포먼스 속도가 더 빠르다는것을 알 수 있다.
하지만 index값으로 조회 시 ArrayList의 속도가 더 빠르다.
(사진에서 말하는 LInkedList index는 ArrayList의 index 개념적인 차이가 있다.)
That’s not the same as saying “it can directly search using index of the object” – because it can’t.
Typically O(1) access by index is performed by using an array lookup, and in the case of a linked list there isn’t an array – there’s just a chain of nodes. To access a node with index N, you need to start at the head and walk along the chain N times… which is an O(N) operation.
(출처: https://stackoverflow.com/questions/31498848/do-elements-in-linkedlist-class-of-java-have-index)
직역하자면 LinkedList는 불연속적으로 위치한 각 요소(노드)들을 연결한 리스트이고 ArrayList는 인덱스로 원소를 관리한다. 하지만 링크드리스트를 프로그래밍시 사용되는 인덱스는 논리적인 개념의 인덱스이다. 사용시 ArrayList와 같은 인덱스로 이용되지만 그 원리에 따른 속도차이는 다르다. 조회 시 array는 index의 값을 기준으로 조회하였을 때 시간 복잡도가 O(1)이고 조회시 index로 조회한다는(논리적으로) LinkedList는 O(N)의 속도를 갖고 있어 속도면에서 ArrayList가 빠르다는 것을 알수 있다.
![출처 : [그림1.] JCF 계층구조 - 출처: http://www.java-forums.org](https://blog.kakaocdn.net/dn/EdI7C/btrPJeojTVA/CmkV0OI4oFaKtTQ71umRE1/img.png)
위의 계층 구조를 보면 더 쉽게 알 수 있다. ArrayList는 AbstractList를 상속하고 인덱스를 통한 무작위 접근(Random Access)을 통해 데이터를 조회 할 수 있어 속도가 빠르지만 LinkedList는 Abstract Sequential List를 상속하면서 인덱스가 아닌 순차적접근(Sequential access)으로 데이터를 조회한다. 이는 데이터를 조회시 시작부터 끝까지 데이터를 조회한다는 의미이다. 그렇기에 시간 복잡도에 큰 차이가 있다.
(ArrayList has direct references to every element in the list, so it can get the n-th element in constant time. LinkedList has to traverse the list from the beginning to get to the n-th element.
참조: stackoverflow; performace differences between ArrayList and LinkedList)
그렇다면 ArrayList처럼 조회 시 속도도 빠르고 사용하기 편한 순차적 데이터 연결된 배열 형식으로 되어있는 리스트를 사용하면 되는데 굳이 LinkedList를 사용하는 이유는 무엇일까?
LinkedList의 가장 큰 장점인 삭입, 삭제의 빠른 처리 기능이 있어서이다.


ArrayList의 삽입 삭제을 위에 있는 그림을 보면 삽입 삭제 이전 이후의 데이터들이 뒤로 또는 앞으로 이동하는 것을 알수 있다. 그래서 연산처리 시간 복잡도가 O(N)만큼 시간이 소요된다.
하지만 아래와 같이 LinkedList는 여러개의 노드들이 각각의 포인트의 주소값을 가르키면서 서로 연결되어 있는 구조이기 때문에 삽입, 삭제 시 해당하는 참조 노드들만 변경 혹은 수정하기만 하면 된다. 그래서 시간 복잡도는 O(1)만큼의 연산 속도가 걸리는 것이다.

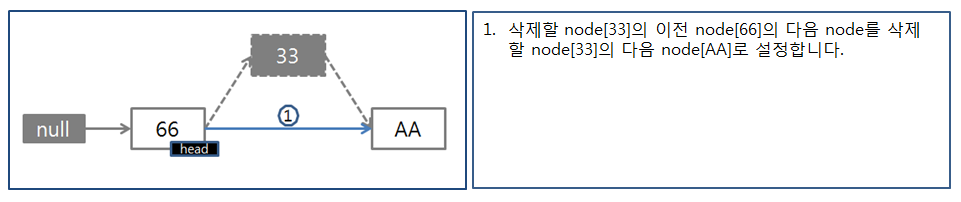
여기 까지가 오늘 공부한 내용을 정리하면서 여러 블로그 분들의 자료를 취합해서 생각을 정리해봤다.
2일차는 해당 정의된 정보를 가지고 코드로 구현해보고자 한다.
추가적 내용 :
참조의 지역성(Locality of reference; 전산 이론중의 하나로 한번 참조된 데이터는 다시 참조될 가능성이 높고 참조된 데이터 주변의 데이터 역시 같이 참조될 가능성이 높다는 이론)
에 따르면 많은 블로거 분들이 참조의 지역성 관련해서 정확하지 않는 설명이 있어 자세하게 알아보았는데
참조의 지역성 관련해서 ArrayList 와 LinkedList의 차이를 설명한 블로거 중
https://scahp.tistory.com/37 이분의 설명이 제일 와닿았다.
여러 자료를 찾아는 보았지만 아직 참조의 지역성 관련해서 퍼포먼스 측면의 속도는 물리적 관점에서 요즘 시대의 서버사양이 향상 되면서 과연 어떤게 더 좋을지는 아직까지는 잘 모르겠다.