
오늘은 [Kafka] 카프카란? 2편 – 심화편(실습) 입니다. 앞서 kafka 카프카에 대해서 – 1 . 카프카에 대한 간략한 설명을 했습니다. 오늘은 카프카를 더 자세히 알려드리겠습니다.
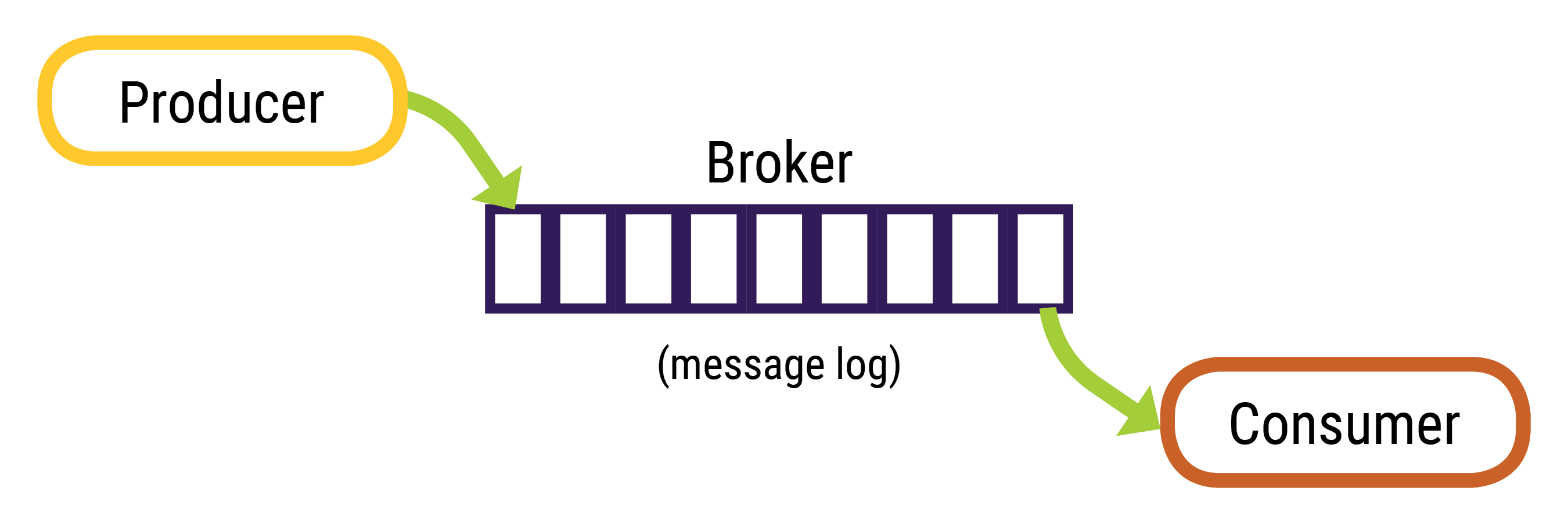
Kafka의 구조와 메시지 처리
-
프로듀서와 파티셔너
- 프로듀서는 데이터를 브로커에 전송합니다.
- 파티셔너는 토픽과 레코드의 키를 기반으로 어느 파티션에 저장할지 결정합니다.
- 메시지 키가 있는 경우 해시 함수를 사용해 파티션 할당합니다.
- 메시지 키가 없는 경우 라운드로빈 방식으로 파티션을 선택합니다.
-
사용자 정의 파티셔너

- 사용자는 직접 파티셔너를 구현할 수 있습니다.
- 특별한 요구 사항에 대응하는 파티셔너를 구현 가능합니다.
-
AMQP와 우선순위 처리
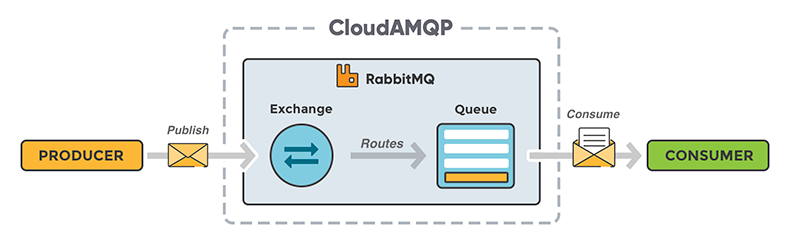
- AMQP를 통해 우선순위 지원 가능.
- 우선순위가 높은 메시지를 먼저 처리합니다.
Kafka의 Lag 모니터링
-
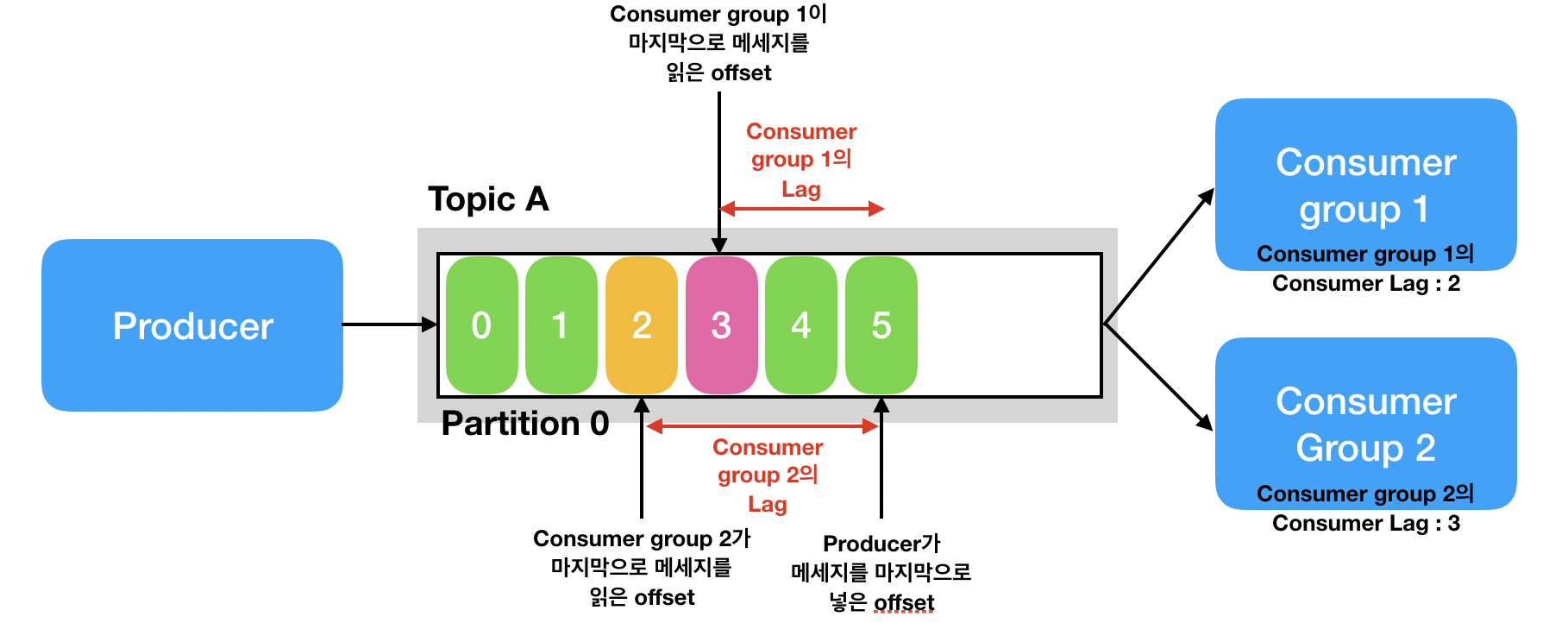
Lag의 정의
- 컨슈머가 메시지를 가져가지 못한 오프셋의 수를 나타냅니다.
- 프로듀서 오프셋과 컨슈머 오프셋의 차이로 계산됩니다.
-
Lag의 중요성
- 컨슈머의 성능 저하와 연관됩니다.
- 정확한 모니터링을 통해 최적화가 가능합니다.
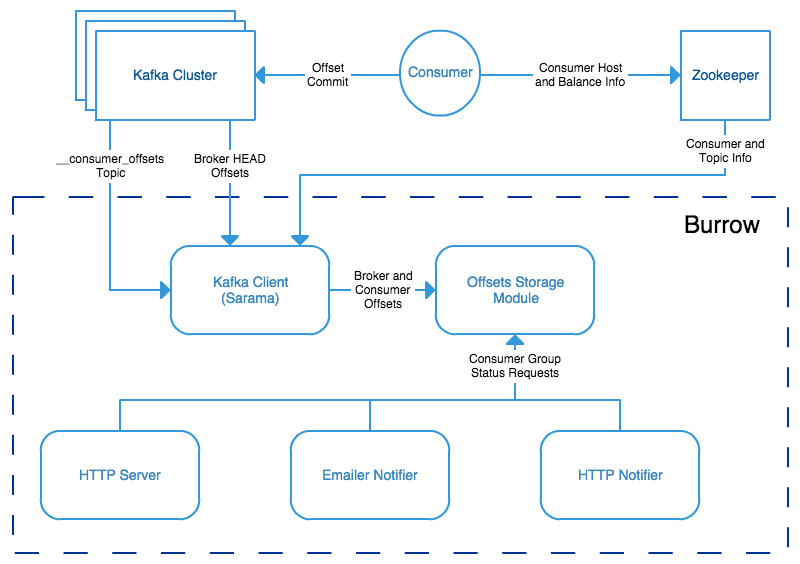
벌어(Burrow)와 컨슈머 렉 모니터링
-
벌어의 정의
- 멀티 카프카 클러스터 지원
- 컨슈머 랙 모니터링을 위한 독립적 애플리케이션
- 데이터 저장 및 추후 활용
-
벌어의 역할
- 카프카 클러스터 내 컨슈머 렉을 모니터링하는 도구입니다.
- 멀티 클러스터 지원과 슬라이딩 윈도우 기능 제공.
-
httpd API의 활용
- 벌어에서 수집한 정보를 조회합니다.
- 추가적인 데이터 저장 및 생태계 구축 가능
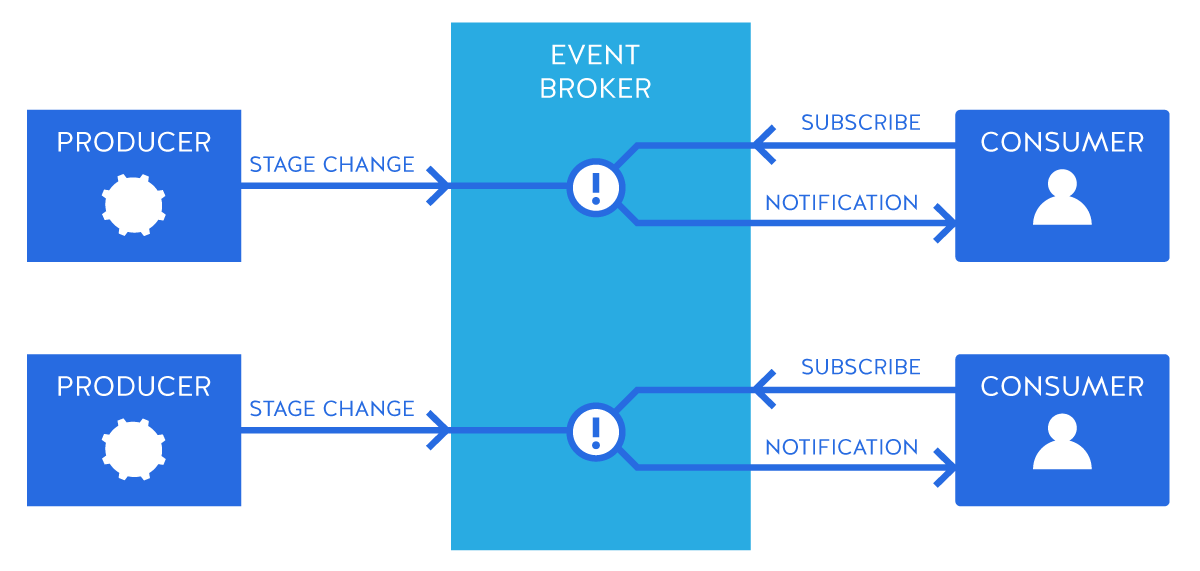
메시지 큐와 이벤트 브로커의 차이점
-
이벤트 브로커
- 인덱스를 통한 메시지 보관
- 장애 복구 지원
- 다양한 이벤트 기반 마이크로 서비스 활용
-
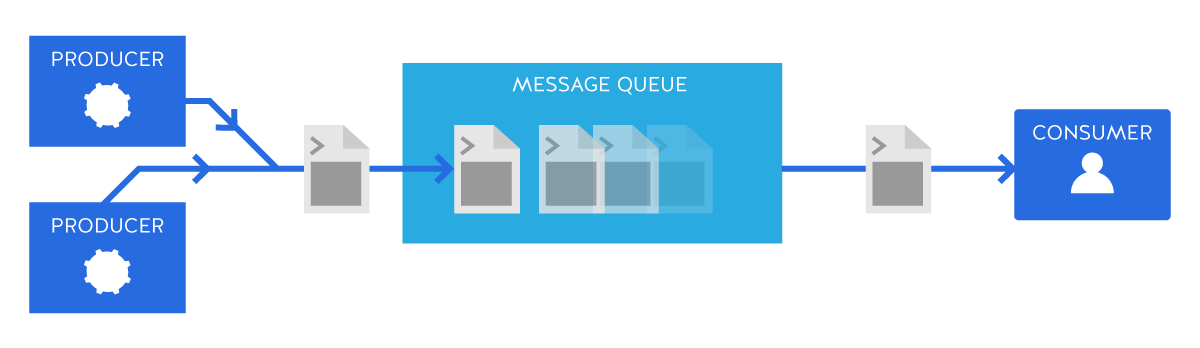
메시지 큐
- 대규모 메시지 기반 미들웨어 사용
- 메시지 처리 후 삭제
- 연결 효율성 강화
Kafka 클러스터 구축 실습
-
AWS EC2 서버 사용
- 가상 머신을 이용한 카프카 클러스터 구축
- 1개 노드로 구성된 클러스터 구축
-
애플리케이션 설치 및 설정
- 주키퍼와 카프카 설치
- 시큐리티 그룹 설정 및 포트 열기
- 서버 간 연동 설정
-
카프카 클러스터 구축 실습
- AWS C2 서버 설정
- AWS 계정 로그인 후 EC2 대시보드로 이동합니다.
- 인스턴스 생성을 클릭하여 적절한 리전 및 인스턴스 유형을 선택합니다.
- 여기서는 테스트 목적으로 T2 마이크로 인스턴스를 선택합니다.
- 가상 머신을 이용한 카프카 클러스터 구축
- 1개 노드로 구성된 클러스터를 선택하고, OS로 Ubuntu를 선택합니다.
- 애플리케이션 설치 및 설정
- 주키퍼 설치
- AWS C2 서버 설정
-
주키퍼 압축 파일을 다운로드 받아 압축을 푸는 작업을 수행합니다.
wget http://apache.mirrors.tds.net/zookeeper/zookeeper-3.4.13/zookeeper-3.4.13.tar.gz tar -xzf zookeeper-3.4.13.tar.gz mv zookeeper-3.4.13 /usr/local/zookeeper
-
주키퍼 설정 파일을 수정합니다.
cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
-
카프카 설치
-
카프카 압축 파일을 다운로드 받아 압축을 푸는 작업을 수행합니다.
wget https://downloads.apache.org/kafka/2.8.0/kafka_2.13-2.8.0.tgz tar -xzf kafka_2.13-2.8.0.tgz mv kafka_2.13-2.8.0 /usr/local/kafka
- 시큐리티 그룹 설정 및 포트 열기
- AWS EC2 대시보드에서 인스턴스의 보안 그룹을 선택합니다.
- 인바운드 규칙을 편집하여 2181, 2888, 3888, 9092 포트를 열어줍니다.
- 서버 간 연동 설정
- 주키퍼와 카프카 설정 파일을 수정하여 서버 간 연동을 설정합니다.
- 주키퍼를 실행합니다.
/usr/local/zookeeper/bin/zkServer.sh start
카프카 서버를 실행합니다.
/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties
이제 카프카 클러스터가 구축되었으며, 필요한 추가 설정과 테스트를 수행할 수 있습니다.