
풀스택 개발자가 되기 위해서는 데이터 베이스에 대한 이해도도 높아야 합니다. 그래서 오늘은 MySQL 인덱스의 이해: 정의, 목적, 저장 방식 및 장단점에 대해서 말하고자 합니다.
정의: 인덱스란 무엇인가?

인덱스(Index)는 데이터베이스에서 데이터를 빠르게 검색할 수 있도록 도와주는 자료 구조입니다. 이는 사전의 색인과 유사하게 작동하며, 키와 값의 쌍으로 구성됩니다.
목적: 왜 인덱스를 사용하는가?
인덱스의 주된 목적은 원하는 검색어를 더 빠르게 찾기 위한 것입니다. 중요한 부분은 데이터의 정렬입니다.
정렬의 종류
- SortedList: 항상 정렬된 상태로 유지되는 자료 구조로, DBMS의 인덱스와 같은 자료 구조입니다.
- ArrayList: 값이 저장된 순서대로 정렬됩니다.

ArrayList 저장방식이다.
SortedList의 장단점
- 단점: 데이터 저장 시마다 값을 정렬해야 하므로 처리 비용이 발생할 수 있습니다.
- 장점: 이미 정렬되어 있으므로, 원하는 값을 아주 빠르게 찾아올 수 있습니다.
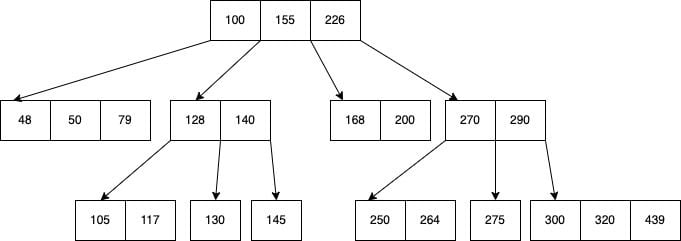
저장 방식: 어떻게 인덱스가 저장되는가?
알고리즘
- B-Tree 알고리즘: 일반적인 알고리즘으로, 칼럼의 값을 변형하지 않고 원래 값을 이용해 인덱싱합니다.
- R-Tree 알고리즘: MySQL에서 위치 기반 검색을 지원합니다.
- Hash 인덱스: 매우빠른 검색을 지원하지만, 값을 변형해서 인덱싱하므로 일부 검색에는 제한이 있습니다.
- Fractal-Tree 인덱스, 로그 기반의 Merge-Tree 인덱스: 고급 인덱싱 기술입니다.
중복 허용 여부
- 유니크 인덱스(Unique): 특정 값에 대한 중복을 허용하지 않으며, 효율적인 검색이 가능합니다.
- 논 유니크 인덱스(Non-Unique): 중복 값을 허용합니다.
기능
- 전문 검색용 인덱스: 특별한 검색 요구사항을 위한 인덱스입니다.
결론
인덱스는 데이터 검색 속도를 향상시키는 중요한 도구입니다. 올바른 인덱스 설계와 관리는 시스템의 성능을 크게 향상시킬 수 있으며, 개발자와 데이터베이스 관리자에게 필수적인 기술입니다.
Redis – 서론, 확장성, 장애회복성의 역할 또한 읽어보시면서 대용량 서비스를 처리하기 위한 고성능의 메모리 내 캐싱 시스템에 대해서도 읽어보시길 바랍니다.